CVPR作为计算机视觉和模式识别领域的世界级学术顶会,不仅是学者们展示前沿科技成果的学术会议,也是企业界探索前沿应用的一大平台。近年来,随着大模型技术的爆发式发展,基于大模型技术的创新应用正逐步在产业界释放出巨大价值空间。
作为人工智能技术领域的领军者与深耕者,百度在大模型技术领域拥有强大的技术优势和深厚技术积累,截至2022年11月,百度自主研发的产业级知识增强大模型体系文心大模型已经包含36个大模型,涵盖基础大模型、任务大模型、行业大模型三级体系,全面满足产业应用需求,构建了业界规模最大的产业大模型体系。作为文心大模型的核心之一,文心·CV大模型VIMER已广泛应用在自动驾驶、云智一体、移动生态等核心业务。
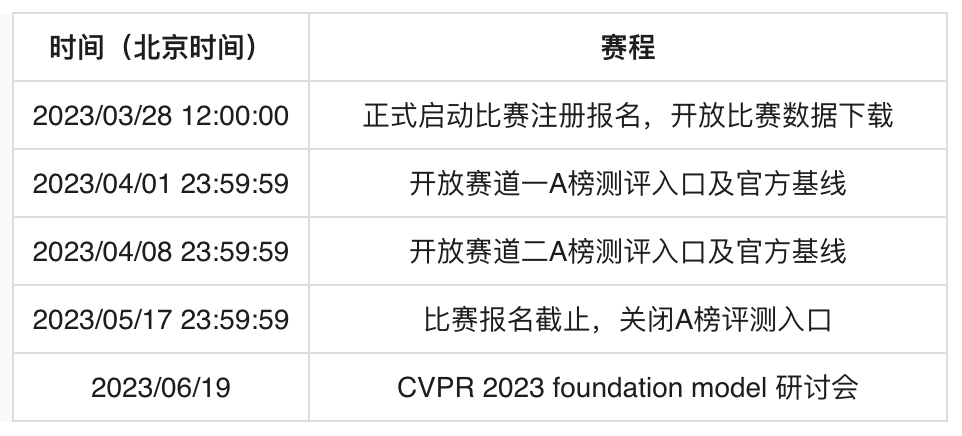
为了进一步推动视觉大模型技术的发展,今年百度将在CVPR 2023上举办首届大模型workshop,邀请大模型领域内的顶级学者和精英们共同探讨大模型技术的现状和未来,同时将在智能交通领域举办首个多任务大模型的国际比赛,提供大模型应用技术交流和切磋的平台。我们于2023年3月28日正式启动第一届大模型技术国际竞赛,向全球开发者开放报名通道。(大赛地址请见文末)
本次大模型技术竞赛我们瞄准智能交通方向,开源了Open-TransMind v1.0给选手作为比赛基线,为全球挑战者切磋交流前沿大模型技术提供绝佳机会。
百度在2022年中提出了统一特征表示优化技术(UFO:Unified FeatureOptimization),并发布了当年全球最大视觉模型VIMER-UFO 2.0(文心·CV大模型),覆盖20+ CV 基础任务,实现了28项公开数据集 SOTA,随后百度Apollo将UFO技术以及智能交通AI能力共同整合为多模态多场景多任务的文心交通大模型之【ERNIE-Traffic-TransMind】,可同时支持点云、视觉、文本三种模态,包含自动驾驶、车路协同、智慧交管、智能网联、智慧停车、智慧高速等多种场景下的百余种交通特性,并且开创式引入了文本图像对话的开放世界理解能力和文本图像模态转化能力,目前已陆续应用到了百度智能交通的各类解决方案和产品线中。
 赛题背景
近年来,智慧汽车、人工智能等产业发展,为智能交通发展创造了良好的发展机遇。智能交通相关技术已经渗透到我们的日常生活中,但是现有大模型的多任务处理模式以及传统的感知方法(如分类、检测、分割等)无法满足我们对更广交通场景以及更高自动驾驶水平的追逐。我们从当前实际技术研究中的关键问题出发,设置了两大赛道:
赛题背景
近年来,智慧汽车、人工智能等产业发展,为智能交通发展创造了良好的发展机遇。智能交通相关技术已经渗透到我们的日常生活中,但是现有大模型的多任务处理模式以及传统的感知方法(如分类、检测、分割等)无法满足我们对更广交通场景以及更高自动驾驶水平的追逐。我们从当前实际技术研究中的关键问题出发,设置了两大赛道:
之前主流的视觉模型生产流程,通常采用单任务“trainfrom scratch” 方案。每个任务都从零开始训练,各个任务之间也无法相互借鉴。由于单任务数据不足带来偏置问题,实际效果过分依赖任务数据分布,场景泛化效果往往不佳。近两年蓬勃发展的大数据预训练技术,通过使用大量数据学到更多的通用知识,然后迁移到下游任务当中,本质上是不同任务之间相互借鉴了各自学到的知识。基于海量数据获得的预训练模型具有较好的知识完备性,在下游任务中基于少量数据 fine-tuning 依然可以获得较好的效果。不过基于预训练+下游任务 fine-tuning 的模型生产流程,需要针对各个任务分别训练模型,存在较大的研发资源消耗。
百度提出的 VIMER-UFO All in One 多任务训练方案,通过使用多个任务的数据训练一个功能强大的通用模型,可被直接应用于处理多个任务。不仅通过跨任务的信息提升了单个任务的效果,并且免去了下游任务 fine-tuning 过程。VIMER-UFO All in One 研发模式可被广泛应用于各类多任务 AI 系统,以智慧城市场景为例,VIMER-UFO 可以用单模型实现人脸识别、人体和车辆ReID等多个任务的 SOTA 效果,同时多任务模型可获得显著优于单任务模型的效果,证明了多任务之间信息借鉴机制的有效性。
在交通场景中高性能的图像检索能力对于交通执法、治安治理具有十分重要的作用,传统的图像检索方式通常使用先对图像进行属性识别再通过与期望属性的对比实现检索能力。随着多模态大模型技术的发展,文本与图像的表征统一和模态转换已有广泛应用,使用该能力可以进一步提升图像检索的精度和灵活性。
 赛题详情
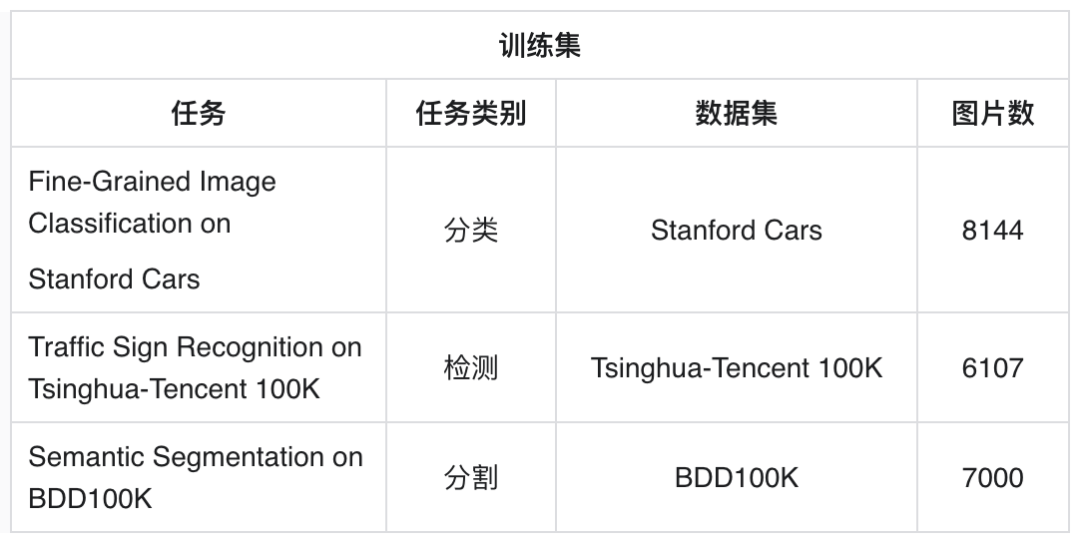
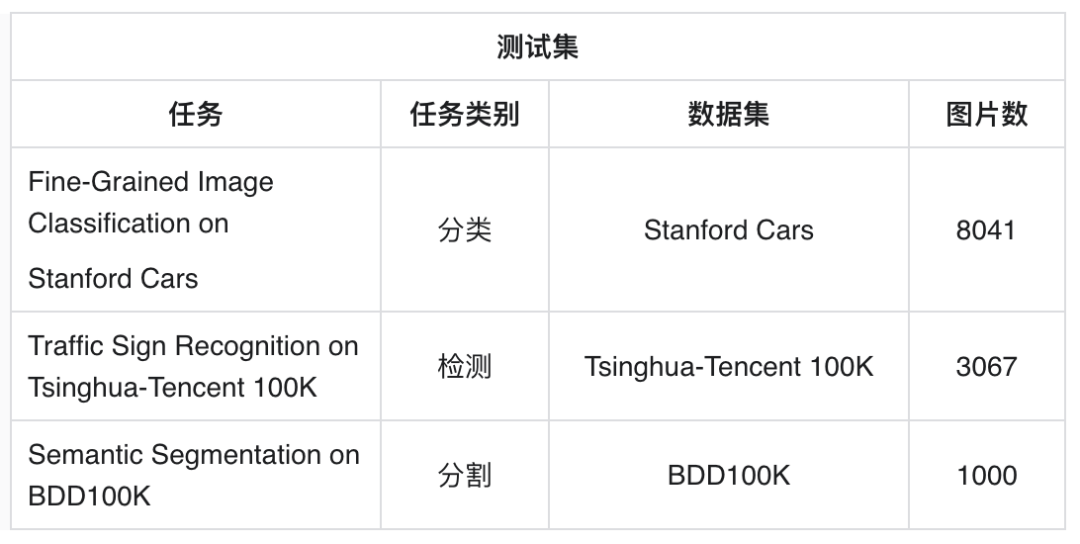
本赛道旨在解决多任务、多数据的合并冲突问题。对于设计精良的网络结构和损失函数,多个任务共同训练能大幅提升模型的泛化性。由于特定任务的数据存在noise,仅使用单一任务的数据进行训练,存在过拟合的风险。统一多任务大模型通过将多个任务的数据整合进行统一训练,能够对不同任务的noise做一个平均,进而使模型学到更好的特征。为了进一步探索统一多任务大模型的能力上限,本赛道以交通场景典型任务为题,覆盖了分类、检测、分割三大类CV任务至单一大模型中,使得单一大模型具备能力的同时获得领先于特定单任务模型的性能。最终All in One大模型在分类、检测、分割任务上的加权指标会作为获奖标准。
本赛题则基于交通场景,选择了分类、检测、分割三大代表性任务进行All in One联合训练。参赛选手们需要根据给出的分类、检测、分割三任务的数据集,使用统一大模型进行All in One联合训练,使得单一模型能够具备分类、检测、分割的能力。
赛题详情
本赛道旨在解决多任务、多数据的合并冲突问题。对于设计精良的网络结构和损失函数,多个任务共同训练能大幅提升模型的泛化性。由于特定任务的数据存在noise,仅使用单一任务的数据进行训练,存在过拟合的风险。统一多任务大模型通过将多个任务的数据整合进行统一训练,能够对不同任务的noise做一个平均,进而使模型学到更好的特征。为了进一步探索统一多任务大模型的能力上限,本赛道以交通场景典型任务为题,覆盖了分类、检测、分割三大类CV任务至单一大模型中,使得单一大模型具备能力的同时获得领先于特定单任务模型的性能。最终All in One大模型在分类、检测、分割任务上的加权指标会作为获奖标准。
本赛题则基于交通场景,选择了分类、检测、分割三大代表性任务进行All in One联合训练。参赛选手们需要根据给出的分类、检测、分割三任务的数据集,使用统一大模型进行All in One联合训练,使得单一模型能够具备分类、检测、分割的能力。
赛道二
本赛道旨在
提升文本图像检索的精度
。在交通场景中高性能的图像检索能力对于交通执法、治安治理具有十分重要的作用,传统的图像检索方式通常使用先对图像进行属性识别再通过与期望属性的对比实现检索能力。随着多模态大模型技术的发展,文本与图像的表征统一和模态转换已有广泛应用,使用该能力可以进一步提升图像检索的准确性和灵活性。
本赛道旨在提升交通场景中文本图像检索的精度。因此我们将多种公开数据集中的交通参与者图像进行了文本描述标注从而
构建了多对多的图像-文本对
,选手可以在此基础上进行多模态技术的研究工作,提升文本检索图像的精度。
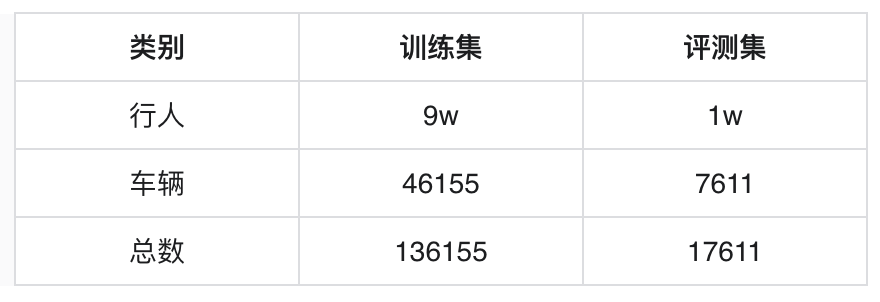
本赛题构建了一个多交通参与者的文本检索图像数据集,该数据集以开源数据集为基础,同时使用网络爬虫技术扩充数据的丰富度。在标注方面,首先利用CV大模型丰富图像标注属性,然后利用大语言模型构造图像对应的文本标注。目前数据集的总量有153766张,其中训练集136155张,评测集17611张。数据集包含行人和车辆2大类,数据分布具体见下表:
 为了降低研究者参与挑战赛的门槛,我们为每个赛道提供了数据说明、评估指标与复现脚本,更多详细信息请关注文末大赛详情页。
本次大赛
总奖池10,000美元
,每个赛道奖池各5,000美元。两个赛道中获得前三名的团队均会予以丰厚的资金奖励,同时获奖团队将会受邀参加在
加拿大温哥华举行的CVPR 2023 Foundation Model Workshop 颁奖典礼
(也可线上参加),
在workshop上宣讲团队技术方案、提交论文
(可以不通过cmt系统提交,仅限extended abstract论文) 。
作为人工智能技术领域的领军者与深耕者,百度在大模型技术领域拥有强大的技术优势和深厚应用积累。通过此次竞赛,百度期望与全球开发者就大模型技术展开广泛交流与学习,共同推进大模型技术的发展。
百度飞桨作为中国首个自主研发、功能丰富、开源开放的产业级深度学习平台,为本次竞赛参赛者提供了平台和GPU算力等技术支持,助力AI人才破除参赛桎梏。除了“以赛促学”、通过竞赛挖掘AI人才外,百度以飞桨为创新基座构建起涵盖学习、实践、比赛、认证、就业在内的全周期服务体系。
今年的竞赛为各位参赛者提供了丰富的参赛专属福利:报名即可免费申领100h Tesla V100 GPU算力(团队中每位成员均可领取)。
为了降低研究者参与挑战赛的门槛,我们为每个赛道提供了数据说明、评估指标与复现脚本,更多详细信息请关注文末大赛详情页。
本次大赛
总奖池10,000美元
,每个赛道奖池各5,000美元。两个赛道中获得前三名的团队均会予以丰厚的资金奖励,同时获奖团队将会受邀参加在
加拿大温哥华举行的CVPR 2023 Foundation Model Workshop 颁奖典礼
(也可线上参加),
在workshop上宣讲团队技术方案、提交论文
(可以不通过cmt系统提交,仅限extended abstract论文) 。
作为人工智能技术领域的领军者与深耕者,百度在大模型技术领域拥有强大的技术优势和深厚应用积累。通过此次竞赛,百度期望与全球开发者就大模型技术展开广泛交流与学习,共同推进大模型技术的发展。
百度飞桨作为中国首个自主研发、功能丰富、开源开放的产业级深度学习平台,为本次竞赛参赛者提供了平台和GPU算力等技术支持,助力AI人才破除参赛桎梏。除了“以赛促学”、通过竞赛挖掘AI人才外,百度以飞桨为创新基座构建起涵盖学习、实践、比赛、认证、就业在内的全周期服务体系。
今年的竞赛为各位参赛者提供了丰富的参赛专属福利:报名即可免费申领100h Tesla V100 GPU算力(团队中每位成员均可领取)。
 点击放大图片扫描二维码
点击放大图片扫描二维码
大模型技术在智能交通领域的创新,将不断满足人们对于安全便捷、高质量出行的期待。CVPR 2023大模型赛道为全球各地的参赛者们提供了理想的展示技术和创新的舞台。
我们诚挚欢迎智能交通、大模型领域的专业人士、研究人员、学生以及相关企业参加本次竞赛,为解决交通领域关键科技问题打开新视角、产生新思想、提出新方法。期待在
CVPR 2023
颁奖典礼上与您相见!