
飞桨原生推理库Paddle Inference
在实际应用中,推理阶段会面临和训练时完全不一样的硬件环境,当然也对应着不一样的计算性能要求。我们训练得到的模型,需要能在具体生产环境中正确、高效地实现推理功能,完成上线部署。 上线部署可能会遇到各种问题,比如:
- 预测面临特殊硬件环境:上线部署的硬件环境和训练时不同。
- 业务系统是多语言环境:业务系统使用C++或者Java实现,不是Python。
- 模型性能(速度和大小)需优化:推理计算耗时太高, 可能造成服务不可用。模型的内存占用过高造成无法上线。
对工业级部署而言,要求的条件往往非常繁多而且苛刻,不是每个深度学习框架在实际生产部署上都能有良好的支持。飞桨提供了一系列的模型部署工具和方案,可以让用户的模型上线工作事半功倍。
Paddle Inference是什么
Paddle Inference是飞桨原生推理库,使用静态图或者动态图保存Inference模型,在C++后端调用模型,并部署到高性能的业务系统中。
飞桨框架的推理部署能力经过多个版本的升级迭代,形成了完善的推理库Paddle Inference。Paddle Inference功能特性丰富、性能优异,针对不同平台不同应用场景进行了深度的适配优化,做到高吞吐、低时延,保证了飞桨模型在服务器端即训即用,快速部署。
针对前面提到的几个模型部署问题, Paddle Inference 提供了对应的解决方案:
-
主流软硬件环境兼容适配
支持服务器端X86 CPU、NVIDIA GPU芯片,兼容Linux/MAC OS/Windows系统。
-
多语言环境丰富接口可灵活调用
支持C++, Python, C, Go和R语言API, 接口简单灵活,20行代码即可完成部署。可通过Python API,实现对性能要求不太高的场景快速支持;通过C++高性能接口,可与线上系统联编;通过基础的C API可扩展支持更多语言的生产环境。
-
多种性能优化策略
- 内存/显存复用提升服务吞吐量:在推理初始化阶段,对模型中的OP输出Tensor 进行依赖分析,将两两互不依赖的Tensor在内存/显存空间上进行复用,进而增大计算并行量,提升服务吞吐量。
- 细粒度OP横向纵向融合减少计算量:在推理初始化阶段,按照已有的融合模式将模型中的多个OP融合成一个OP,减少了模型的计算量的同时,也减少了 Kernel Launch的次数,从而提升推理性能。目前Paddle Inference支持的融合模式多达几十个。
- 内置高性能的CPU/GPU Kernel:内置同Intel、NVIDIA共同打造的高性能kernel,保证了模型推理高性能的执行。
- 子图集成TensorRT加快GPU推理速度:Paddle Inference采用子图的形式集成TensorRT,针对GPU推理场景,TensorRT可对一些子图进行优化,包括OP的横向和纵向融合,过滤冗余的OP,并为OP自动选择最优的kernel,加快推理速度。 注释:TensorRT是英伟达针对GPU提供的高性能的深度学习推理优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。
- 支持加载PaddleSlim量化压缩后的模型:PaddleSlim是飞桨深度学习模型压缩工具,Paddle Inference可联动PaddleSlim,支持加载量化、裁剪和蒸馏后的模型并部署,由此减小模型存储空间、减少计算占用内存、加快模型推理速度。
Paddle Inference场景划分
Paddle Inference应用场景,按照API接口类型可以分C++, Python, C, Go和R。
Python适合直接应用,可通过Python API实现性能要求不太高的场景的快速支持;C++接口属于高性能接口,可与线上系统联编。C接口是基于C++,用于支持更多语言的生产环境。
不同接口的使用流程是一致的,仅语言写法上的不同以及个别操作细节存在差异。其中,比较常见的场景是C++和Python。
Paddle Inference C++ 接口的部署流程
模型部署首先要有部署的模型文件。在模型训练过程中或者模型训练结束后,可以通过save_inference_model 接口来导出标准化的模型文件。save_inference_model可以根据推理需要的输入和输出, 对训练模型进行剪枝, 去除和推理无关部分, 得到的模型相比训练时更加精简, 适合进一步优化和部署。注意,读者在之前章节接触到的paddle.save和paddle.load接口,更多是用于模型训练后测试预测效果,而追求高性能的上线系统,优先推荐Paddle inference产品提供的接口。
其中,静态图和动态图的保存模型API接口不同,如下案例所展示。
- 静态图保存模型
paddle.static.save_inference_model(path_prefix="./sample_model", feed_vars=[image], fetch_vars=[out], executor=exe)
-
动态图保存模型 Paddle 2.0做动态图模型保存的方式跟1.8版本存在很大差异, 请先确认使用框架为2.0以后版本。由于部署工具只支持静态图保存的模型格式,所以动态图的模型程序需要通过“动转静”功能将模型保存成静态图的格式。Paddle2.0支持透过to_static装饰器模式及to_static直接函数调用两种方式完成动态图转静态图的部署,以下分别详述:
1. tostatic裝飾器模式:
动转静 paddle.jit.to_static 装饰器支持 input_spec 参数,用于指定被装饰函数每个 Tensor 类型输入参数的 shape 、 dtype 、 name 等签名信息。不必再显式地传入 Tensor 数据以触发网络层 shape 的推导。 Paddle 会解析 to_static 中指定的 input_spec 参数,构建网络的起始输入,进行后续的模型组网。同时,借助 input_spec 参数,可以自定义输入 Tensor 的 shape ,比如指定 shape 为 [None, 784] ,其中 None 表示变长的维度。
如下是一个简单的使用样例:
# 导入Paddle相关包
import paddle
from paddle.jit import to_static
from paddle.static import InputSpec
from paddle.nn import Layer
# 定义线性回归网络,继承自paddle.nn.Layer
# 该网络仅包含一层fc
class SimpleNet(Layer):
# 在__init__函数中仅初始化linear层
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
# 在forward函数中定义该网络的具体前向计算;@to_static装饰器用于依次指定参数x和y对应Tensor签名信息
# 下述案例是输入为10个特征,输出为1维的数字
@to_static(input_spec=[InputSpec(shape=[None, 10], name='x'), InputSpec(shape=[1], name='y')])
def forward(self, x, y):
out = self.linear(x)
out = out + y
return out
net = SimpleNet()
# 保存预测格式模型
paddle.jit.save(net, './simple_net')
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and W0506 15:07:20.690174 141 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0506 15:07:20.695869 141 gpu_context.cc:272] device: 0, cuDNN Version: 7.6.
在上述的样例中, to_static 装饰器中的 input_spec 为一个 InputSpec 对象组成的列表,用于依次指定参数 x 和 y 对应的 Tensor 签名信息。在实例化 SimpleNet 后,可以直接调用 paddle.jit.save 保存静态图模型,不需要执行任何其他的代码。
2. to_static函数调用模式: 若期望在动态图下训练模型,在训练完成后保存预测模型,并指定预测时需要的签名信息,则可以选择在保存模型时,直接调用 to_static 函数。使用样例如下:
# 定义线性回归网络,继承自paddle.nn.Layer
# 该网络仅包含一层fc
class SimpleNet(Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
# 在forward函数中定义该网络的具体前向计算
def forward(self, x, y):
out = self.linear(x)
out = out + y
return out
net = SimpleNet()
# 训练过程 (伪代码)
for epoch_id in range(10):
train_step(net, train_reader)
# 直接调用to_static函数,paddle会根据input_spec信息对forward函数进行递归的动转静,得到完整的静态图模型
net = to_static(net, input_spec=[InputSpec(shape=[None, 10], name='x'), InputSpec(shape=[1], name='y')])
# 保存预测格式模型
paddle.jit.save(net, './simple_net')
如果不需要使用静态图的模式训练,第二种方式更加简单便捷,可以优先采用。
使用Paddle Inference进行推理部署的流程
在保存好模型之后,使用C++程序调用预测模型的步骤如下图所示。
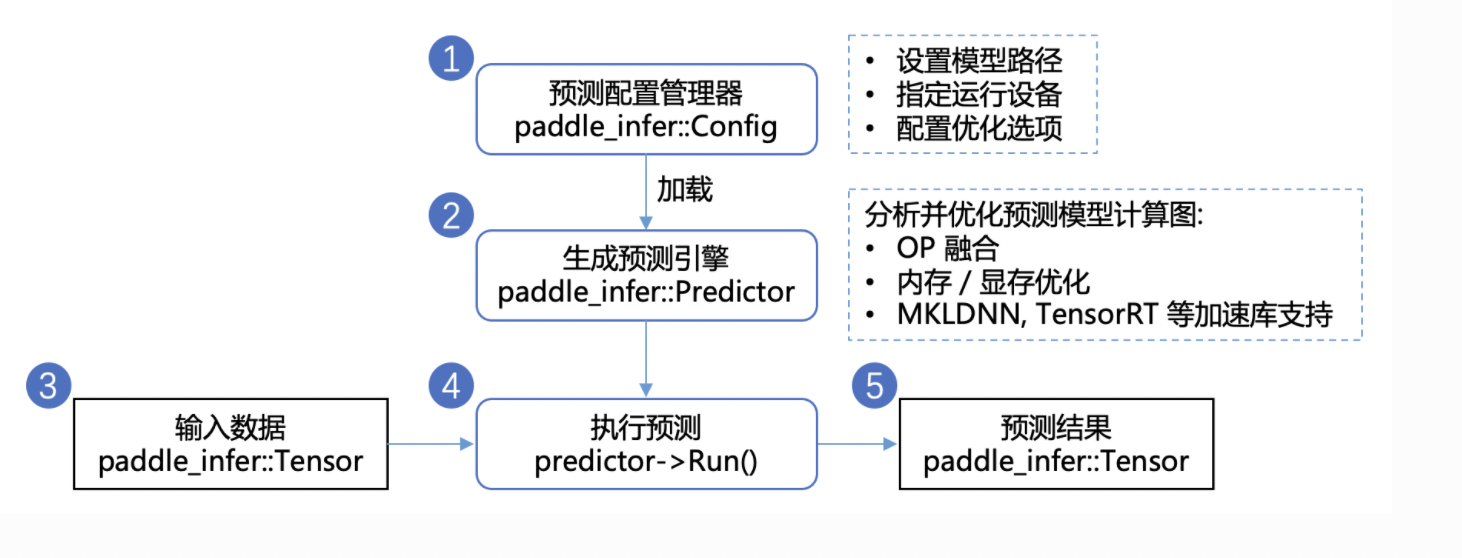
- 配置推理选项。
paddle_infer::Config是飞桨提供的配置管理器API。在使用Paddle Inference进行推理部署过程中,需要使用paddle_infer::Config详细地配置推理引擎参数,包括但不限于在何种设备(CPU/GPU)上部署、加载模型路径、开启/关闭计算图分析优化、使用MKLDNN/TensorRT进行部署的加速等。(注释:MKLDNN是Intel为了CPU推出的深度学习加速库,对标NVIDIA为GPU推出的深度学习加速库TensorRT) - 创建
paddle_infer::Predictor。paddle_infer::Predictor是飞桨提供的推理引擎API。根据设定好的推理配置paddle_infer::Config创建推理引擎paddle_infer::Config,也就是推理引擎的一个实例。创建期间会进行模型加载、分析和优化等工作。 - 准备输入数据。准备好待输入推理引擎的数据,首先获得模型中每个输入的名称以及指向该数据块(CPU或GPU上)的指针,再根据名称将对应的数据块拷贝进
paddle_infer::Tensor。飞桨采用paddle_infer::Tensor作为输入/输出数据结构,可以减少额外的拷贝,提升推理性能。 - 调用Predictor->Run执行推理。
- 获取推理输出。与输入数据类似,根据输出名称将输出的数据(矩阵向量)由
paddle_infer::Tensor拷贝至(CPU或GPU上)以进行后续的处理。 - 最后,获取输出并不意味着预测过程的结束,在一些特别的场景中,单纯的矩阵向量不能让使用者明白它有什么意义。进一步地,我们需要根据向量本身的意义,解析数据,获取实际的输出。举个例子,transformer 翻译模型,我们将字词变成向量输入到预测引擎中,而预测引擎反馈给我们的,仍然是矩阵向量。但是这些矩阵向量是有意义的,我们需要利用这些向量去找翻译结果所对应的句子,才能完成了使用 transformer 翻译的过程。 如上是使用的基本流程,如果需要实际使用Paddle Inference在自己的C++程序中完成模型预测,具体使用方法和示例可参考下述文档。
注:Paddle Inference的使用示例可以参考服务器端部署-原生推理库Paddle Inference。
Paddle Inference Python 接口的部署
使用Python预测API与C++预测API相似,主要包括paddle_infer::Config, paddle_infer::Predictor和paddle_infer::Tensor,分别对应于C++ API中同名的数据类型。下面通过加载一个简答模型以及随机输入的方式,展示了如何使用Paddle Inference Python 接口进行模型预测。
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 引用 numpy argparse库
import numpy as np
import argparse
# 创建配置对象,并根据需求配置
config = paddle_infer.Config("simple_net.pdmodel", "simple_net.pdiparams")
# 配置config,不启用gpu
config.disable_gpu()
# 根据Config创建预测对象
predictor = paddle_infer.create_predictor(config)
# 获取输入的名称
input_names = predictor.get_input_names()
# 获取输入handle
x_handle = predictor.get_input_handle(input_names[0])
y_handle = predictor.get_input_handle(input_names[1])
# 设置输入,此处以随机输入为例,用户可自行输入真实数据
fake_x = np.random.randn(1, 10).astype('float32')
fake_y = np.random.randn(1).astype('float32')
x_handle.reshape([1, 10])
x_handle.copy_from_cpu(fake_x)
y_handle.reshape([1])
y_handle.copy_from_cpu(fake_y)
# 运行预测引擎
predictor.run()
# 获得输出名称
output_names = predictor.get_output_names()
# 获得输出handle
output_handle = predictor.get_output_handle(output_names[0])
output_data = output_handle.copy_to_cpu() # return numpy.ndarray
# 打印输出结果
print(output_data)[[1.4893879 0.37497407 0.15106276]]
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass] --- Running analysis [ir_analysis_pass] --- Running IR pass [simplify_with_basic_ops_pass] --- Running IR pass [layer_norm_fuse_pass] --- Fused 0 subgraphs into layer_norm op. --- Running IR pass [attention_lstm_fuse_pass] --- Running IR pass [seqconv_eltadd_relu_fuse_pass] --- Running IR pass [seqpool_cvm_concat_fuse_pass] --- Running IR pass [mul_lstm_fuse_pass] --- Running IR pass [fc_gru_fuse_pass] --- fused 0 pairs of fc gru patterns --- Running IR pass [mul_gru_fuse_pass] --- Running IR pass [seq_concat_fc_fuse_pass] --- Running IR pass [gpu_cpu_squeeze2_matmul_fuse_pass] --- Running IR pass [gpu_cpu_reshape2_matmul_fuse_pass] --- Running IR pass [gpu_cpu_flatten2_matmul_fuse_pass] --- Running IR pass [matmul_v2_scale_fuse_pass] --- Running IR pass [gpu_cpu_map_matmul_v2_to_mul_pass] I0506 15:08:29.650193 141 fuse_pass_base.cc:57] --- detected 1 subgraphs --- Running IR pass [gpu_cpu_map_matmul_v2_to_matmul_pass] --- Running IR pass [matmul_scale_fuse_pass] --- Running IR pass [gpu_cpu_map_matmul_to_mul_pass] --- Running IR pass [fc_fuse_pass] I0506 15:08:29.650962 141 fuse_pass_base.cc:57] --- detected 1 subgraphs --- Running IR pass [repeated_fc_relu_fuse_pass] --- Running IR pass [squared_mat_sub_fuse_pass] --- Running IR pass [conv_bn_fuse_pass] --- Running IR pass [conv_eltwiseadd_bn_fuse_pass] --- Running IR pass [conv_transpose_bn_fuse_pass] --- Running IR pass [conv_transpose_eltwiseadd_bn_fuse_pass] --- Running IR pass [is_test_pass] --- Running IR pass [runtime_context_cache_pass] --- Running analysis [ir_params_sync_among_devices_pass] --- Running analysis [adjust_cudnn_workspace_size_pass] --- Running analysis [inference_op_replace_pass] --- Running analysis [ir_graph_to_program_pass] I0506 15:08:29.654843 141 analysis_predictor.cc:1006] ======= optimize end ======= I0506 15:08:29.654940 141 naive_executor.cc:102] --- skip [feed], feed -> y I0506 15:08:29.654947 141 naive_executor.cc:102] --- skip [feed], feed -> x I0506 15:08:29.655100 141 naive_executor.cc:102] --- skip [tmp_0], fetch -> fetch
飞桨服务化部署框架Paddle Serving
Paddle Serving是飞桨服务化部署框架,能够帮助开发者轻松实现从移动端、服务器端调用深度学习模型的远程预测服务。 Paddle Serving围绕常见的工业级深度学习模型部署场景进行设计,具备完整的在线服务能力,支持的功能包括多模型管理、模型热加载、基于Baidu-RPC的高并发低延迟响应能力、在线模型A/B实验等,并提供简单易用的Client API。Paddle Serving可以与飞桨训练框架联合使用,从而训练与远程部署之间可以无缝过度,让用户轻松实现预测服务部署,大大提升了用户深度学习模型的落地效率。
注:Baidu-RPC是百度官方开源RPC框架,支持多种常见通信协议,提供基于Protobuf的自定义接口体验。
Paddle Serving的优势特色
- 与飞桨训练框架紧密连接,绝大部分飞桨模型可以一键部署;
- 支持工业级的服务能力,例如模型管理、模型热加载、在线A/B测试等;
- 支持分布式键值对索引,助力于大规模稀疏特征作为模型输入(常见于互联网的资讯推荐和商品推荐场景);
- 支持客户端和服务端之间高并发和高效通信;
- 支持多种编程语言开发客户端,例如Golang,C++和Python;
- 可伸缩框架设计,当前以支持飞桨模型部署为主,但用户可以很容易嵌入其他的机器学习库部署在线预测。
使用Paddle Serving成功部署模型后,可以将模型预测(PaddleHub中的预训练模型或用户编写并训练的模型)作为在线服务,预测服务可以通过HTTP或RPC请求访问,可供多种类型的端灵活调用。
Paddle Serving快速使用
下面以波士顿房价预测为例,介绍如何使用PaddleServing部署HTTP和RPC的服务。
- 安装Paddle Serving
其中客户端安装包支持Centos 7和Ubuntu 18,或者您可以使用HTTP服务,这种情况下不需要安装客户端。
!pip install paddle-serving-client==0.6
!pip install paddle-serving-server==0.6Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddle-serving-client==0.6
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ac/2e/798d16d519991dfd9a1985b3c08cf60c86879fe2f1ed7d2eafbf328e270e/paddle_serving_client-0.6.0-cp37-none-any.whl (42.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 42.3/42.3 MB 2.2 MB/s eta 0:00:0000:0100:01
Requirement already satisfied: six>=1.10.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-client==0.6) (1.16.0)
Collecting grpcio-tools<=1.33.2
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/77/1e/91eaee901589ebee04c21df2f551502e7ba946bab99338f77a1f8a4237e1/grpcio_tools-1.33.2-cp37-cp37m-manylinux2014_x86_64.whl (2.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.5/2.5 MB 4.2 MB/s eta 0:00:0000:0100:01
Requirement already satisfied: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-client==0.6) (2.24.0)
Requirement already satisfied: numpy>=1.12 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-client==0.6) (1.19.5)
Requirement already satisfied: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-client==0.6) (3.14.0)
Collecting grpcio<=1.33.2
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/7a/46/d08d8a5d0e0449f541fe9e7a226854019a41a4fa41fd14332e55b0e4394f/grpcio-1.33.2-cp37-cp37m-manylinux2014_x86_64.whl (3.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.8/3.8 MB 2.4 MB/s eta 0:00:0000:0100:01
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->paddle-serving-client==0.6) (1.25.6)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->paddle-serving-client==0.6) (2019.9.11)
Requirement already satisfied: idna<3,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->paddle-serving-client==0.6) (2.8)
Requirement already satisfied: chardet<4,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->paddle-serving-client==0.6) (3.0.4)
Installing collected packages: grpcio, grpcio-tools, paddle-serving-client
Attempting uninstall: grpcio
Found existing installation: grpcio 1.35.0
Uninstalling grpcio-1.35.0:
Successfully uninstalled grpcio-1.35.0
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
parl 1.4.1 requires pyzmq==18.1.1, but you have pyzmq 22.3.0 which is incompatible.
Successfully installed grpcio-1.33.2 grpcio-tools-1.33.2 paddle-serving-client-0.6.0
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddle-serving-server==0.6
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ba/d2/80a742e5d525cf9a25e166d3d61e56d38351e80b63729874b9cc6e08c3d5/paddle_serving_server-0.6.0-py3-none-any.whl (8.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.2/8.2 MB 2.7 MB/s eta 0:00:0000:0100:010m
Collecting Werkzeug==1.0.1
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/cc/94/5f7079a0e00bd6863ef8f1da638721e9da21e5bacee597595b318f71d62e/Werkzeug-1.0.1-py2.py3-none-any.whl (298 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 298.6/298.6 KB 4.3 MB/s eta 0:00:00a 0:00:01
Collecting func-timeout
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/b3/0d/bf0567477f7281d9a3926c582bfef21bff7498fc0ffd3e9de21811896a0b/func_timeout-4.3.5.tar.gz (44 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 44.3/44.3 KB 1.3 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Requirement already satisfied: grpcio-tools<=1.33.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-server==0.6) (1.33.2)
Requirement already satisfied: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-server==0.6) (3.14.0)
Requirement already satisfied: itsdangerous==1.1.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-server==0.6) (1.1.0)
Requirement already satisfied: grpcio<=1.33.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-server==0.6) (1.33.2)
Requirement already satisfied: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-server==0.6) (5.1.2)
Collecting MarkupSafe==1.1.1
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/c2/37/2e4def8ce3739a258998215df907f5815ecd1af71e62147f5eea2d12d4e8/MarkupSafe-1.1.1-cp37-cp37m-manylinux2010_x86_64.whl (33 kB)
Collecting Jinja2==2.11.3
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/7e/c2/1eece8c95ddbc9b1aeb64f5783a9e07a286de42191b7204d67b7496ddf35/Jinja2-2.11.3-py2.py3-none-any.whl (125 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 125.7/125.7 KB 3.5 MB/s eta 0:00:00
Requirement already satisfied: six>=1.10.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-server==0.6) (1.16.0)
Requirement already satisfied: flask>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddle-serving-server==0.6) (1.1.1)
Collecting click==7.1.2
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/d2/3d/fa76db83bf75c4f8d338c2fd15c8d33fdd7ad23a9b5e57eb6c5de26b430e/click-7.1.2-py2.py3-none-any.whl (82 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 82.8/82.8 KB 4.7 MB/s eta 0:00:00
Building wheels for collected packages: func-timeout
Building wheel for func-timeout (setup.py) ... done
Created wheel for func-timeout: filename=func_timeout-4.3.5-py3-none-any.whl size=15077 sha256=2682d5631f17395706b037ab90691398c99b510476c44e56314c1fae0e616d3b
Stored in directory: /home/aistudio/.cache/pip/wheels/ea/6b/56/b7bcacbd1bd8cd29883e7f7a29cbd98b87b2d789b25bae5563
Successfully built func-timeout
Installing collected packages: func-timeout, Werkzeug, MarkupSafe, click, Jinja2, paddle-serving-server
Attempting uninstall: Werkzeug
Found existing installation: Werkzeug 0.16.0
Uninstalling Werkzeug-0.16.0:
Successfully uninstalled Werkzeug-0.16.0
Attempting uninstall: MarkupSafe
Found existing installation: MarkupSafe 2.0.1
Uninstalling MarkupSafe-2.0.1:
Successfully uninstalled MarkupSafe-2.0.1
Attempting uninstall: click
Found existing installation: Click 7.0
Uninstalling Click-7.0:
Successfully uninstalled Click-7.0
Attempting uninstall: Jinja2
Found existing installation: Jinja2 3.0.0
Uninstalling Jinja2-3.0.0:
Successfully uninstalled Jinja2-3.0.0
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
parl 1.4.1 requires pyzmq==18.1.1, but you have pyzmq 22.3.0 which is incompatible.
nbconvert 6.5.0 requires jinja2>=3.0, but you have jinja2 2.11.3 which is incompatible.
nbconvert 6.5.0 requires MarkupSafe>=2.0, but you have markupsafe 1.1.1 which is incompatible.
Successfully installed Jinja2-2.11.3 MarkupSafe-1.1.1 Werkzeug-1.0.1 click-7.1.2 func-timeout-4.3.5 paddle-serving-server-0.6.0
- 保存模型
由于Paddle Serving部署一般需要额外的配置文件,所以Paddle Serving提供了一个save_model的API接口用于保存模型,该接口与save_inference_model类似,但是可将Paddle Serving在部署阶段需要用到的参数与配置文件统一保存打包。
import paddle_serving_client.io as serving_io
serving_io.save_model("housing_model", "housing_client_conf",
{"words": x}, {"prediction": y_predict},
paddle.static.default_main_program())
paddle.static.default_main_program()是静态图中执行图的概念,如果是动态图的模式编写程序,建议采用接下来讲的方案。
如果已使用save_inference_model接口保存好模型,Paddle Serving也提供了inference_model_to_serving接口,该接口可以把已保存的模型转换成可用于Paddle Serving使用的模型文件。
import paddle_serving_client.io as serving_io
serving_io.inference_model_to_serving(dirname=path, serving_server="serving_model", serving_client="client_conf", model_filename=None, params_filename=None)
python -m paddle_serving_client.convert --dirname ./your_inference_model_dir
下面展示一个将“波士顿房价预测模型”部署成在线服务的案例,波士顿房价预测模型实现了基于13个特征值预测房价价格。
# 下载房价数据集
!wget https://paddle-serving.bj.bcebos.com/others/housing.data
# 使用paddle_serving_client.io实现对房价预测模型的保存
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import numpy as np
import os
import random
def load_data():
# 从文件导入数据
datafile = './housing.data'
data = np.fromfile(datafile, sep=' ', dtype=np.float32)
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 记录数据的归一化参数,在预测时对数据做归一化
global max_values
global min_values
global avg_values
max_values = maximums
min_values = minimums
avg_values = avgs
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
class Regressor(paddle.nn.Layer):
# self代表类的实例自身
def __init__(self):
# 初始化父类中的一些参数
super(Regressor, self).__init__()
# 定义一层全连接层,输入维度是13,输出维度是1
self.fc = Linear(in_features=13, out_features=1)
# 网络的前向计算
@paddle.jit.to_static
def forward(self, inputs):
print(inputs.shape)
x = self.fc(inputs)
return x
# 声明定义好的线性回归模型
model = Regressor()
# 开启模型训练模式
model.train()
# 加载数据
training_data, test_data = load_data()
print("train data", len(training_data),len(training_data[0]))
# 定义优化算法,使用随机梯度下降SGD
# 学习率设置为0.01
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
EPOCH_NUM = 10 # 设置外层循环次数
BATCH_SIZE = 10 # 设置batch大小
# 定义外层循环
for epoch_id in range(EPOCH_NUM):
# 在每轮迭代开始之前,将训练数据的顺序随机的打乱
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个batch包含10条数据
mini_batches = [training_data[k:k+BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]
# 定义内层循环
for iter_id, mini_batch in enumerate(mini_batches):
x = np.array(mini_batch[:, :-1]) # 获得当前批次训练数据
y = np.array(mini_batch[:, -1:]) # 获得当前批次训练标签(真实房价)
# 将numpy数据转为飞桨动态图tensor形式
house_features = paddle.to_tensor(x)
prices = paddle.to_tensor(y)
# 前向计算
predicts = model(house_features)
# 计算损失
loss = F.square_error_cost(predicts, label=prices)
avg_loss = paddle.mean(loss)
if iter_id%20==0:
print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy()))
# 反向传播
avg_loss.backward()
# 最小化loss,更新参数
opt.step()
# 清除梯度
opt.clear_grad()
import paddle_serving_client
#paddle_serving_client.io.save_dygraph_model("uci_housing_server", "uci_housing_client", model)--2022-05-06 15:09:42-- https://paddle-serving.bj.bcebos.com/others/housing.data Resolving paddle-serving.bj.bcebos.com (paddle-serving.bj.bcebos.com)... 182.61.200.195, 182.61.200.229, 2409:8c04:1001:1002:0:ff:b001:368a Connecting to paddle-serving.bj.bcebos.com (paddle-serving.bj.bcebos.com)|182.61.200.195|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 49083 (48K) [application/octet-stream] Saving to: ‘housing.data’ housing.data 100%[===================>] 47.93K --.-KB/s in 0.03s 2022-05-06 15:09:42 (1.85 MB/s) - ‘housing.data’ saved [49083/49083] train data 404 14 (10, 13) epoch: 0, iter: 0, loss is: [0.08298179] epoch: 0, iter: 20, loss is: [0.18905902] (4, 13) epoch: 0, iter: 40, loss is: [0.05891756] epoch: 1, iter: 0, loss is: [0.02634136] epoch: 1, iter: 20, loss is: [0.07644827] epoch: 1, iter: 40, loss is: [0.01681827] epoch: 2, iter: 0, loss is: [0.11204497] epoch: 2, iter: 20, loss is: [0.041244] epoch: 2, iter: 40, loss is: [0.1823509] epoch: 3, iter: 0, loss is: [0.04958185] epoch: 3, iter: 20, loss is: [0.06972825] epoch: 3, iter: 40, loss is: [0.11388689] epoch: 4, iter: 0, loss is: [0.02520542] epoch: 4, iter: 20, loss is: [0.05217889] epoch: 4, iter: 40, loss is: [0.02955645] epoch: 5, iter: 0, loss is: [0.05688157] epoch: 5, iter: 20, loss is: [0.05328684] epoch: 5, iter: 40, loss is: [0.02490901] epoch: 6, iter: 0, loss is: [0.01635606] epoch: 6, iter: 20, loss is: [0.16277438] epoch: 6, iter: 40, loss is: [0.02419762] epoch: 7, iter: 0, loss is: [0.03419017] epoch: 7, iter: 20, loss is: [0.10736818] epoch: 7, iter: 40, loss is: [0.00456306] epoch: 8, iter: 0, loss is: [0.05339989] epoch: 8, iter: 20, loss is: [0.01274406] epoch: 8, iter: 40, loss is: [0.02118322] epoch: 9, iter: 0, loss is: [0.06184959] epoch: 9, iter: 20, loss is: [0.01559077] epoch: 9, iter: 40, loss is: [0.01900552]
- 启动服务
启动服务有如下两种模式,读者可根据场景选择。
- HTTP模式:web service,支持平台广,服务器端方便加入前后处理(服务逻辑不仅是模型预测,比如加入用户权限的校验、数据的预处理、根据模型预测结果做进一步计算等内容),但速度慢
- RPC模式:速度快,但不方便加服务逻辑,支持的平台数量略少。
模式1:使用HTTP服务
Paddle Serving提供了一个名为paddle_serving_server.serve的内置python模块,可以使用单行命令启动RPC服务或HTTP服务。如果我们指定参数–name uci,则意味着我们将拥有一个HTTP服务,其URL为 $IP:$PORT/uci/prediction。
这个启动服务命令的主要参数有四个:
- model:用的模型文件。
- thread:最大并发数。
- port:服务端口。
- name:服务的访问名称。
# 此段代码在AI Studio上运行无法停止,需要手动中止再运行下面的部分
# 可以在本地上后台运行
!python -m paddle_serving_server.serve --model uci_housing_model --thread 10 --port 9292 --name uci/opt/conda/envs/python35-paddle120-env/lib/python3.7/runpy.py:125: RuntimeWarning: 'paddle_serving_server.serve' found in sys.modules after import of package 'paddle_serving_server', but prior to execution of 'paddle_serving_server.serve'; this may result in unpredictable behaviour warn(RuntimeWarning(msg)) This API will be deprecated later. Please do not use it This API will be deprecated later. Please do not use it web service address: http://172.29.162.26:9292/uci/prediction * Serving Flask app "serve" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off Frist time run, downloading PaddleServing components ... --2022-05-06 15:10:21-- https://paddle-serving.bj.bcebos.com/test-dev/bin/serving-cpu-avx-openblas-0.6.0.tar.gz Resolving paddle-serving.bj.bcebos.com (paddle-serving.bj.bcebos.com)... 182.61.200.229, 182.61.200.195, 2409:8c04:1001:1002:0:ff:b001:368a Connecting to paddle-serving.bj.bcebos.com (paddle-serving.bj.bcebos.com)|182.61.200.229|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 90291581 (86M) [application/octet-stream] Saving to: ‘serving-cpu-avx-openblas-0.6.0.tar.gz’ serving-cpu-avx-ope 100%[===================>] 86.11M 31.5MB/s in 2.7s 2022-05-06 15:10:24 (31.5 MB/s) - ‘serving-cpu-avx-openblas-0.6.0.tar.gz’ saved [90291581/90291581] Decompressing files .. Going to Run Comand /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle_serving_server/serving-cpu-avx-openblas-0.6.0/serving -enable_model_toolkit -inferservice_path workdir -inferservice_file infer_service.prototxt -max_concurrency 0 -num_threads 10 -port 12000 -precision fp32 -use_calib False -reload_interval_s 10 -resource_path workdir -resource_file resource.prototxt -workflow_path workdir -workflow_file workflow.prototxt -bthread_concurrency 10 -max_body_size 67108864 I0100 00:00:00.000000 371 op_repository.h:68] RAW: Succ regist op: GeneralCopyOp I0100 00:00:00.000000 371 op_repository.h:68] RAW: Succ regist op: GeneralDistKVInferOp I0100 00:00:00.000000 371 op_repository.h:68] RAW: Succ regist op: GeneralDistKVQuantInferOp I0100 00:00:00.000000 371 op_repository.h:68] RAW: Succ regist op: GeneralInferOp I0100 00:00:00.000000 371 op_repository.h:68] RAW: Succ regist op: GeneralReaderOp I0100 00:00:00.000000 371 op_repository.h:68] RAW: Succ regist op: GeneralResponseOp I0100 00:00:00.000000 371 op_repository.h:68] RAW: Succ regist op: GeneralTextReaderOp I0100 00:00:00.000000 371 op_repository.h:68] RAW: Succ regist op: GeneralTextResponseOp I0100 00:00:00.000000 371 service_manager.h:79] RAW: Service[LoadGeneralModelService] insert successfully! I0100 00:00:00.000000 371 load_general_model_service.pb.h:333] RAW: Success regist service[LoadGeneralModelService][PN5baidu14paddle_serving9predictor26load_general_model_service27LoadGeneralModelServiceImplE] I0100 00:00:00.000000 371 service_manager.h:79] RAW: Service[GeneralModelService] insert successfully! I0100 00:00:00.000000 371 general_model_service.pb.h:1507] RAW: Success regist service[GeneralModelService][PN5baidu14paddle_serving9predictor13general_model23GeneralModelServiceImplE] I0100 00:00:00.000000 371 factory.h:155] RAW: Succ insert one factory, tag: PADDLE_INFER, base type N5baidu14paddle_serving9predictor11InferEngineE W0100 00:00:00.000000 371 paddle_engine.cpp:29] RAW: Succ regist factory: ::baidu::paddle_serving::predictor::FluidInferEngine<PaddleInferenceEngine>->::baidu::paddle_serving::predictor::InferEngine, tag: PADDLE_INFER in macro! --- Running analysis [ir_graph_build_pass] --- Running analysis [ir_graph_clean_pass] --- Running analysis [ir_analysis_pass] --- Running analysis [ir_params_sync_among_devices_pass] --- Running analysis [adjust_cudnn_workspace_size_pass] --- Running analysis [inference_op_replace_pass] --- Running analysis [memory_optimize_pass] --- Running analysis [ir_graph_to_program_pass] ^C
其他命令的参数介绍如下表所示。
| Argument | Type | Default | Description |
|---|---|---|---|
thread |
int | 4 |
Concurrency of current service |
port |
int | 9292 |
Exposed port of current service to users |
name |
str | "" |
Service name, can be used to generate HTTP request url |
model |
str | "" |
Path of paddle model directory to be served |
mem_optim |
bool | False |
Enable memory optimization |
ir_optim |
bool | False |
Enable analysis and optimization of calculation graph |
use_mkl (Only for cpu version) |
bool | False |
Run inference with MKL |
可通过如下网址 $IP:$PORT/uci/prediction 直接访问预测服务,通过feed和fetch变量设定模型输入和输出。我们可使用 curl 命令来发送HTTP POST请求给刚刚启动的服务。
当然,用户也可以调用Python库来发送HTTP POST请求,请参考Python库Request。
curl -H "Content-Type:application/json" -X POST -d '{"feed":[{"x": [0.0137, -0.1136, 0.2553, -0.0692, 0.0582, -0.0727, -0.1583, -0.0584, 0.6283, 0.4919, 0.1856, 0.0795, -0.0332]}], "fetch":["price"]}' http://127.0.0.1:9292/uci/prediction
模式2:使用RPC服务
用户还可以使用paddle_serving_server.serve启动RPC服务。 尽管用户需要基于Paddle Serving的python客户端API进行一些开发,但是RPC服务通常比HTTP服务更快。当该命令没有指定–name时,使用的就是RPC服务。
# 在终端中运行这段代码
!python -m paddle_serving_server.serve --model uci_housing_model --thread 10 --port 9292
使用RPC服务则需要在访问预测服务的客户端写程序,同时客户端需事先安装paddle Serving client。 但客户端程序极为简单,仅用如下十行代码即可完成。
# A user can visit rpc service through paddle_serving_client API
# client.py文件中代码如下,此段程序不要在notebook里运行,仅作为展示
from paddle_serving_client import Client
client = Client()
client.load_client_config("uci_housing_client/serving_client_conf.prototxt")
client.connect(["127.0.0.1:9292"])
data = [0.0137, -0.1136, 0.2553, -0.0692, 0.0582, -0.0727,
-0.1583, -0.0584, 0.6283, 0.4919, 0.1856, 0.0795, -0.0332]
fetch_map = client.predict(feed={"x": data}, fetch=["price"])
print(fetch_map)
另开一个终端,输入命令
python client.py
客户端程序通过配置文件serving_client_conf.prototxt 设定更多高级功能。 在声明了一个client实例后,client通过connect([“IP:PORT”])连接服务器,并使用predict获取预测结果。 在这里,client.predict函数具有两个参数。 feed是带有模型输入变量别名和值的python dict。fetch要从服务器返回的预测变量赋值。 在该示例中,在训练过程中保存可服务模型时,被赋值的tensor名为"x"和"price"。
往届优秀学员作品展示
CascadeRCNN和YOLOv3_Enhance的布匹瑕疵检测模型训练部署
- 项目背景
产品质量不稳定的问题一直困扰着我国许多传统制造业企业,而传统的质量管理手段实际执行时需要大量的人力资源、管理资源投入进行保障,并且,只是降低问题发生的概率,并不能够完全杜绝质量问题发生。 随着人工智能和计算机视觉等技术突飞猛进,诞生了工业质检的应用场景,如果能够将这些技术应用于各行各业,尤其是半导体、纺织、快速消费品等质量要求严格或劳动强度大的行业,将创造巨大的商业价值。
- 项目内容
本文聚焦于纺织行业的布匹疵点智能检测场景,使用PaddleDetection中CascadeRCNN和YOLOv3的增强模型进行训练、预测,大幅提升预测速度,并提供了多种模型部署方式,使模型具备在工业场景的落地能力,以期为各种工业质检场景提供解决方案示例。
- 实现方案
使用PaddleDetection结合Cascade RCNN,使用更大的训练与评估尺度(1000x1500),最终在单卡V100上速度为20FPS,COCO mAP达47.8%。并将模型导出,接到C++服务器端预测库或Serving服务。
- 实现结果

- 项目点评
基于PaddleClas中SSLD蒸馏方案训练得到的ResNet50_vd预训练模型,结合PaddleDetection中的丰富算子,面向服务器端实用的目标检测方案PSS-DET,使CascadeRCNN增强模型在预测速度上逼近YOLOv3增强模型,效果非常显著。并在Serving上进行工业部署,完成度十分高,实际意义很大。