
Sparse update
paddle.nn.functional.embedding <cn_api_paddle_nn_functional_embedding> layer supports “sparse updates” in both single-node and distributed training, which means gradients are stored in a sparse tensor structure where only rows with non-zero gradients are saved. In distributed training, for larger embedding layers, sparse updates reduce the amount of communication data and speed up training.
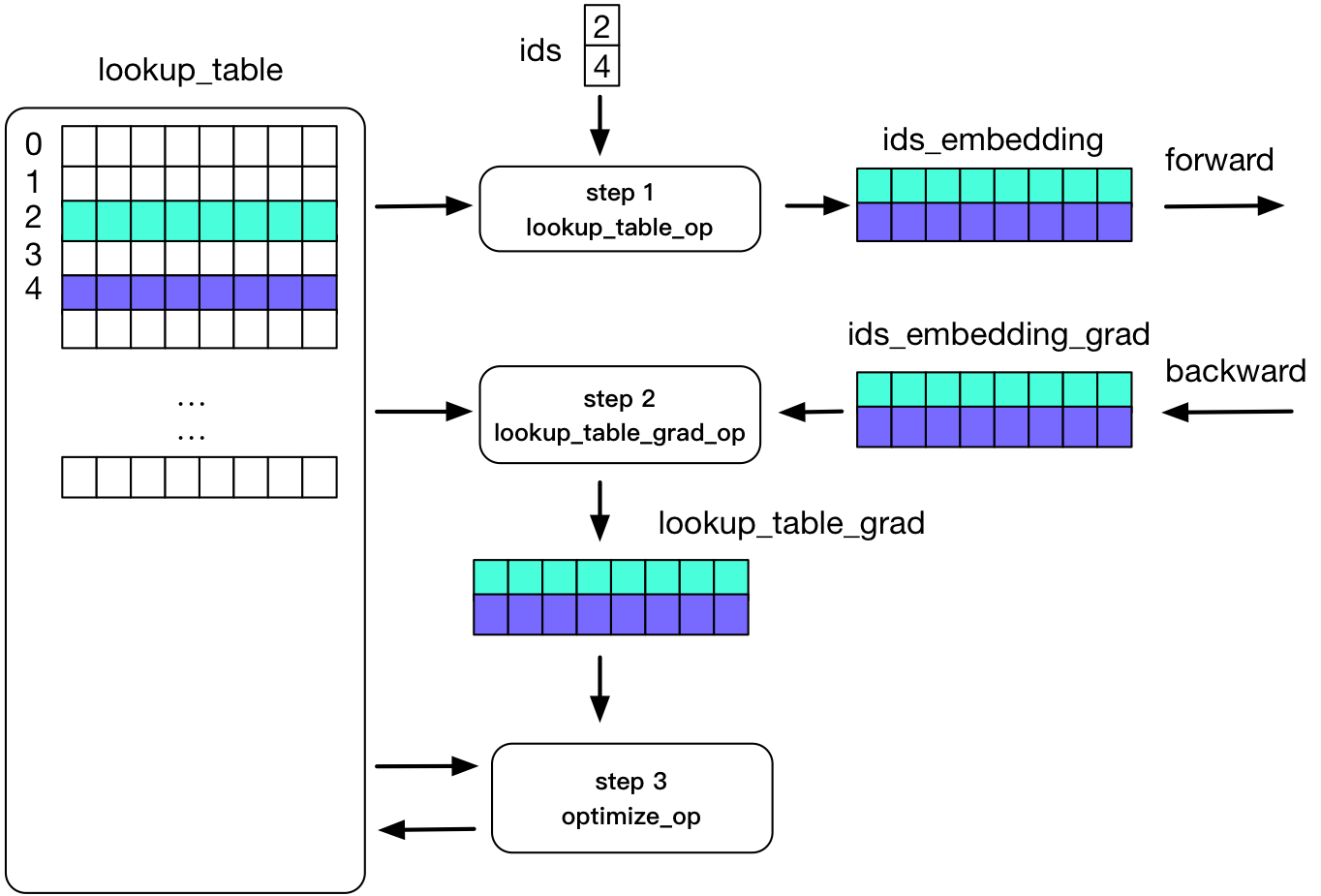
In paddle, we use lookup_table to implement embedding. The figure below illustrates the process of embedding in the forward and backward calculations:
As shown in the figure: two rows in a Tensor are not 0. In the process of forward calculation, we use ids to store rows that are not 0, and use the corresponding two rows of data for calculation; the process of backward update is only to update the two lines.
Example
API reference paddle.nn.functional.embedding <cn_api_paddle_nn_functional_embedding> .