
broadcast
- paddle.distributed. broadcast ( tensor: Tensor, src: int, group: Group | None = None, sync_op: bool = True ) task [source]
-
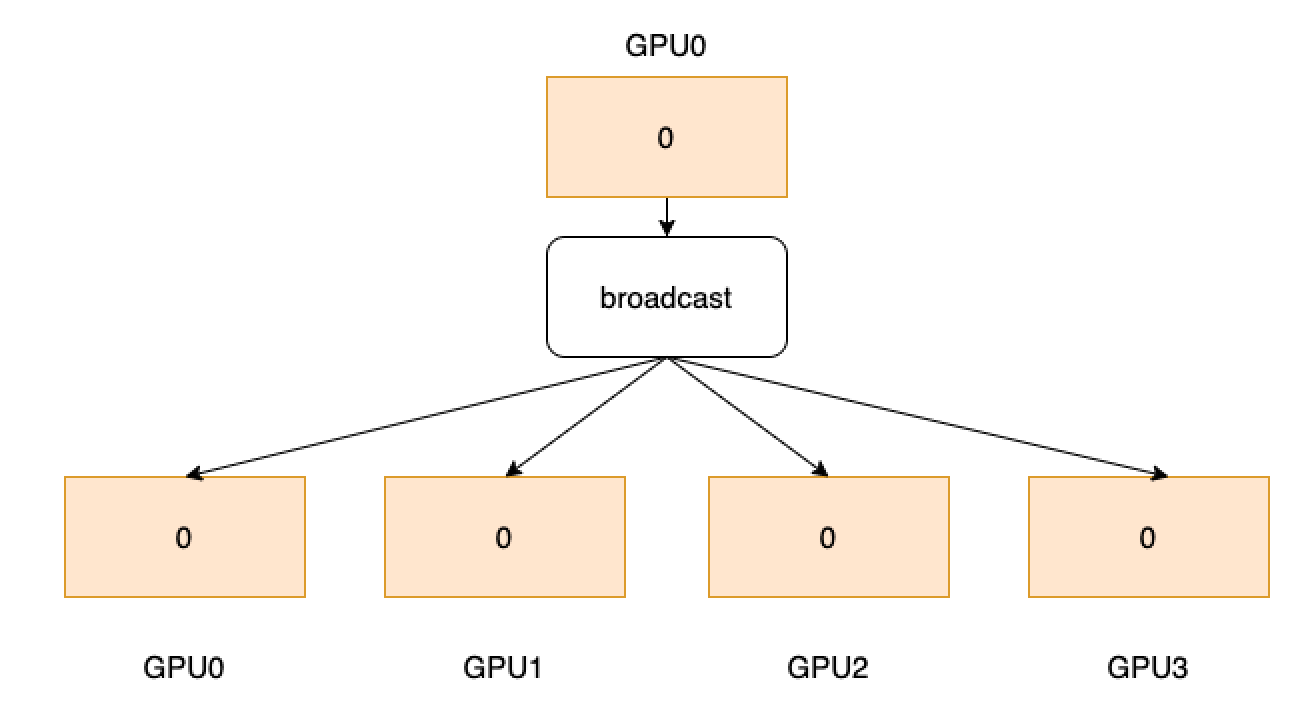
Broadcast a tensor from the source to all others. As shown below, one process is started with a GPU and GPU0 owns data 0. Through broadcast operator, data 0 will be sent to all GPUs from GPU0.
- Parameters
-
tensor (Tensor) – The tensor to send if current rank is the source, or the tensor to receive otherwise. Its data type should be float16, float32, float64, int32, int64, int8, uint8, bool, bfloat16, complex64 or complex128.
src (int) – The source rank in global view.
group (Group, optional) – The group instance return by new_group or None for global default group.
sync_op (bool, optional) – Whether this op is a sync op. The default value is True.
- Returns
-
Return a task object.
Examples
>>> >>> import paddle >>> import paddle.distributed as dist >>> dist.init_parallel_env() >>> if dist.get_rank() == 0: ... data = paddle.to_tensor([[4, 5, 6], [4, 5, 6]]) >>> else: ... data = paddle.to_tensor([[1, 2, 3], [1, 2, 3]]) >>> dist.broadcast(data, src=1) >>> print(data) >>> # [[1, 2, 3], [1, 2, 3]] (2 GPUs)