global_gather
- paddle.distributed.utils. global_gather ( x, local_count, global_count, group=None, use_calc_stream=True )
global_gather 根据 global_count 将 x 的数据收集到 n_expert * world_size 个 expert,然后根据 local_count 接收数据。 其中 expert 是用户定义的专家网络,n_expert 是指每张卡拥有的专家网络数目,world_size 是指运行网络的显卡数目。
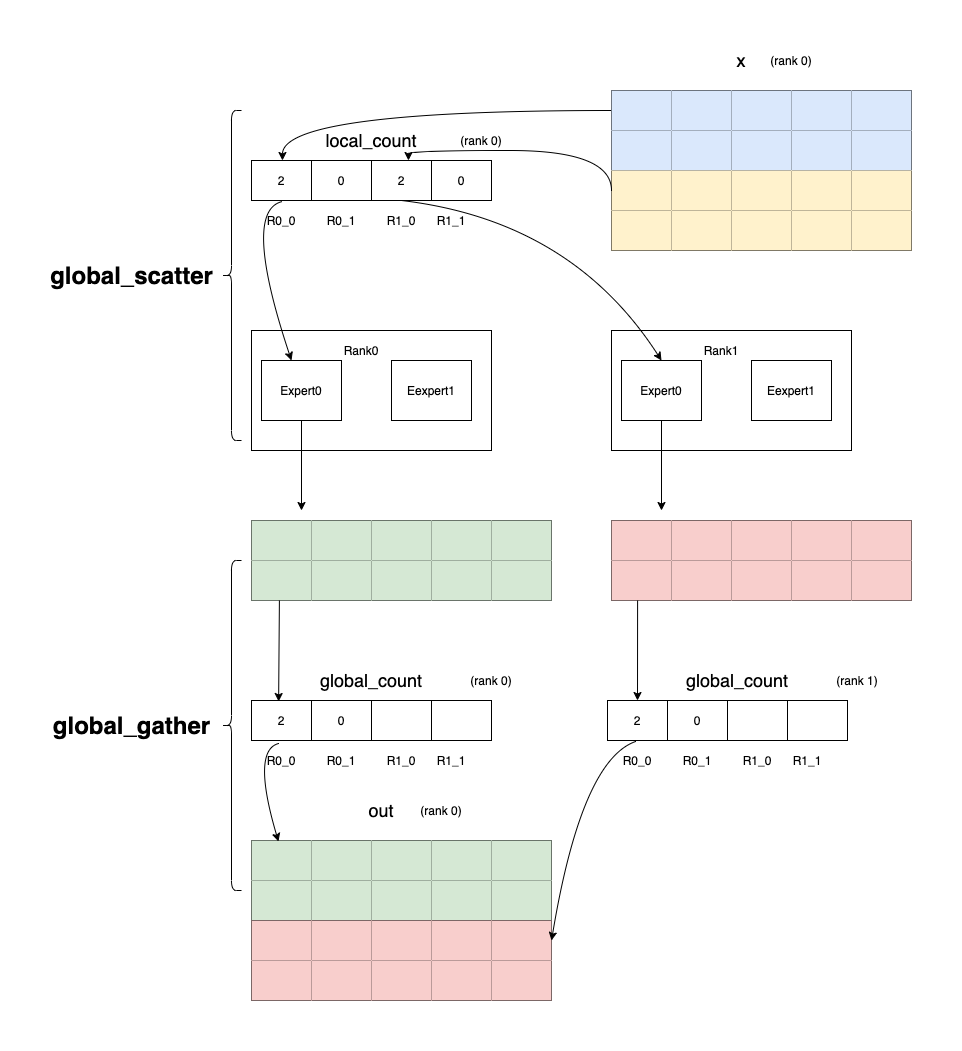
如下图所示,world_size 是 2,n_expert 是 2,x 的 batch_size 是 4,local_count 是[2, 0, 2, 0],0 卡的 global_count 是[2, 0, , ], 1 卡的 global_count 是[2, 0, ,](因为篇幅问题,这里只展示在 0 卡运算的数据),在 global_gather 算子里, global_count 和 local_count 的意义与其在 global_scatter 里正好相反, global_count[i]代表向第 (i // n_expert)张卡的第 (i % n_expert)个 expert 发送 local_expert[i]个数据, local_count[i]代表从第 (i // n_expert)张卡接收 global_count[i]个数据给本卡的 第(i % n_expert)个 expert。 发送的数据会按照每张卡的每个 expert 排列。图中的 rank0 代表第 0 张卡,rank1 代表第 1 张卡。
global_gather 发送数据的流程如下:
第 0 张卡的 global_count[0]代表向第 0 张卡的第 0 个 expert 发送 2 个数据;
第 0 张卡的 global_count[1]代表向第 0 张卡的第 1 个 expert 发送 0 个数据;
第 1 张卡的 global_count[0]代表向第 0 张卡的第 0 个 expert 发送 2 个数据;
第 1 张卡的 global_count[1]代表向第 0 张卡的第 1 个 expert 发送 0 个数据。
参数
x (Tensor) - 输入 Tensor。Tensor 的数据类型必须是 float16、float32、 float64、int32、int64。
local_count (Tensor) - 拥有 n_expert * world_size 个数据的 Tensor,用于表示有多少数据接收。Tensor 的数据类型必须是 int64。
global_count (Tensor) - 拥有 n_expert * world_size 个数据的 Tensor,用于表示有多少数据发送。Tensor 的数据类型必须是 int64。
group (Group,可选) - new_group 返回的 Group 实例,或者设置为 None 表示默认地全局组。默认值:None。
use_calc_stream (bool,可选) - 标识使用计算流还是通信流。默认值:True,表示用计算流。
返回
Tensor,从所有 expert 接收的数据。
代码示例
COPY-FROM: paddle.distributed.utils.global_gather