稀疏更新
paddle.nn.functional.embedding <cn_api_paddle_nn_functional_embedding> 层在单机训练和分布式训练时,均可以支持“稀疏更新”,即梯度以 sparse tensor 结构存储,只保存梯度不为 0 的行。 在分布式训练中,对于较大的 embedding 层,开启稀疏更新有助于减少通信数据量,提升训练速度。
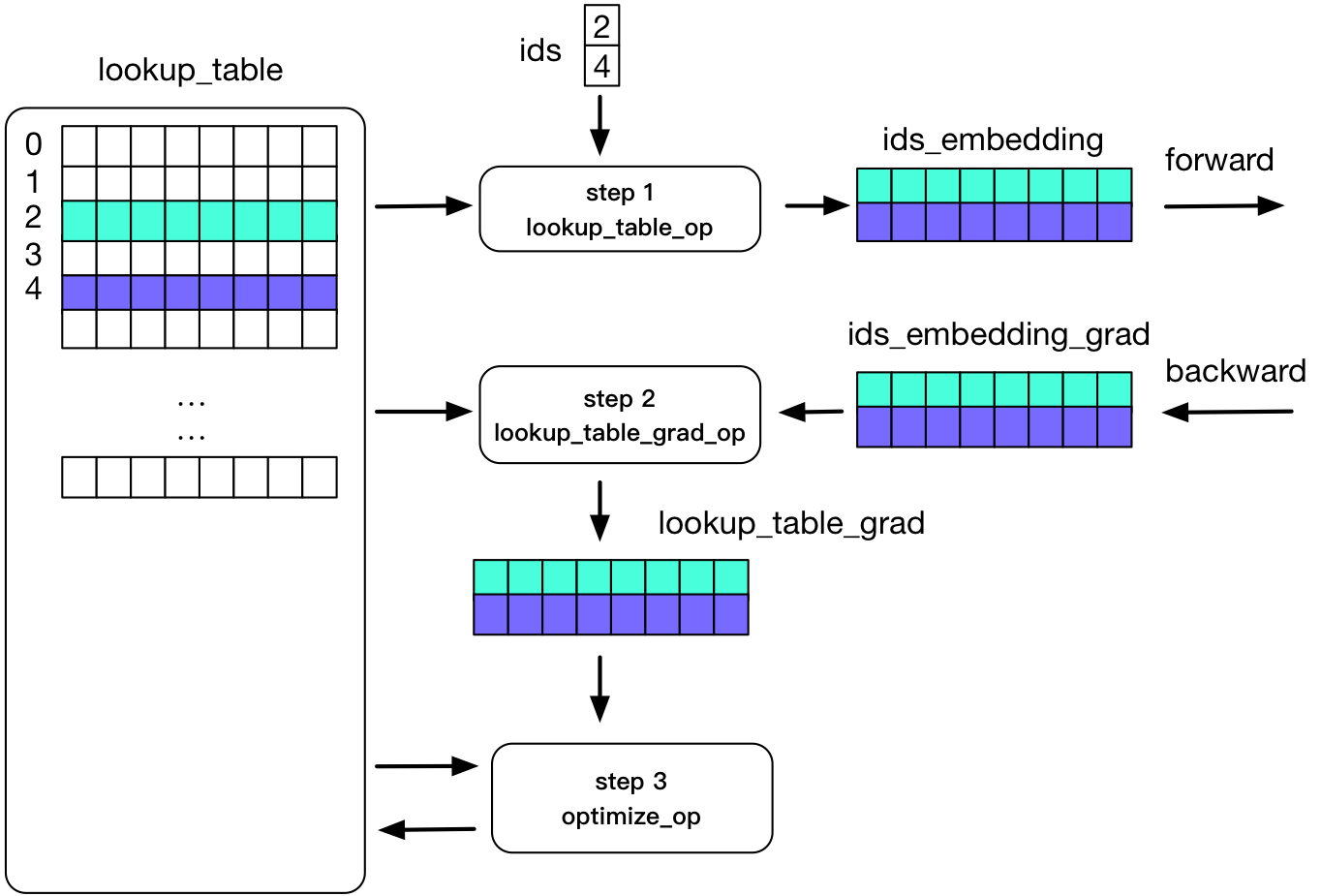
在 paddle 内部,我们用 lookup_table 来实现 embedding。下边这张图说明了 embedding 在正向和反向计算的过程:
如图所示:一个 Tensor 中有两行不为 0,正向计算的过程中,我们使用 ids 存储不为 0 的行,并使用对应的两行数据来进行计算;反向更新的过程也只更新这两行。
API 详细使用方法参考 paddle.nn.functional.embedding <cn_api_paddle_nn_functional_embedding>